我最近越来越相信:真正把 AI 用开的人,迟早都会给自己搭一套‘第二大脑’
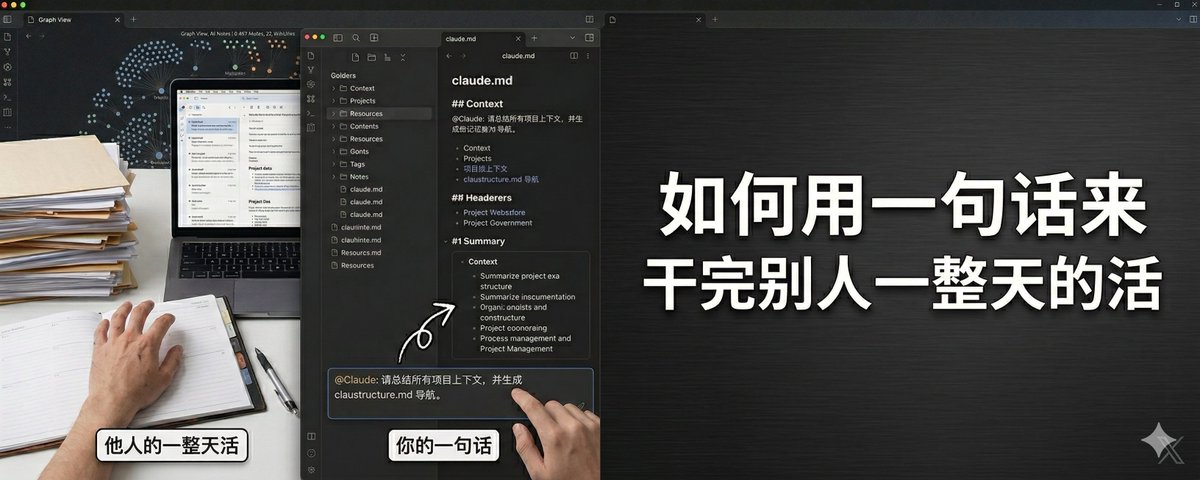
我最近越来越强烈地感觉到,人与人之间后面真正拉开 AI 使用差距的,不只是模型会不会写,而是谁更早把自己的项目、偏好、决策和资料沉淀成一套可持续调用的上下文系统。
我最近越来越相信:真正把 AI 用开的人,迟早都会给自己搭一套“第二大脑”
前两天我看到一个思路,看完以后最大的感受不是“这招很炫”,而是:
这可能才是普通人把 AI 真正用出效率差的分水岭。
为什么我会这么说?
因为我自己最近越来越明显地感受到一个问题:
现在很多人都在高频用 AI,但大部分人的用法,其实还停留在“临时聊天工具”阶段。
每开一个新对话,背景都要重新讲一遍:
- 我是做什么的
- 我的项目做到哪了
- 我的客户是谁
- 我的内容风格是什么
- 哪些词我不想用
- 这周我最优先的事情是什么
每次都重新输入一遍,真的很蠢。
说难听点,很多人不是在用 AI,而是在反复给 AI 做入职培训,而且这个新员工每天早上都会失忆一次。
我为什么会被“第二大脑 + AI”这套玩法打动
我最认同的一点,是它不是在教你怎么问一个更花哨的 prompt,而是在解决一个更本质的问题:
怎么让 AI 不再每次都从零开始。
这件事一旦解决,效率提升不是一点点。
因为很多工作里真正浪费时间的,不是生成本身,而是前面的上下文补课。
你让 AI 写内容,先得交代受众、调性、品牌、背景、目标; 你让 AI 帮你看项目,先得交代项目进度、优先级、会议结论、卡点; 你让 AI 帮你分析一个复杂问题,先得把前因后果重新讲一遍。
来回几次以后你就会发现,AI 本身没那么慢,慢的是每次都要重新把自己介绍给它。
所以我现在越来越认可一种玩法:
别只想着怎么问得更聪明,先把你的长期上下文沉淀下来。
这套系统最强的地方,不是回答问题,而是“记住你”
我觉得这套玩法最厉害的地方,不在于它能不能生成一篇文章,而在于它能不能逐步变成一个真正了解你的系统。
比如你今天在对话里随口说一句:
- 以后写东西别用破折号
- 写文案别太油
- 面向老板的内容要更直接
- 我的用户更关心赚钱,不关心概念
如果这些规则说完就散了,那它们永远只是一次性沟通。
但如果这些规则能被持续存回你的知识库里,后面所有调用相关写作技能、分析技能、汇总技能的流程,都会自动继承这些偏好。
这时候 AI 才开始真正像一个长期协作对象,而不是一个每次重启的临时工。
我最看重的,是它会越用越值钱
很多工具最大的问题是:你用得再勤,也只是多用几次。
但这种“第二大脑 + AI”的组合不是这样。
它的价值会随着时间累积,原因很简单:
- 你补充的每一条偏好都会被留下来
- 你做过的每一次决策都会成为未来的参考
- 你整理过的每一份资料都能变成下一轮分析的底料
- 你纠正过的每一次错误,后面都有机会不再重复
换句话说,这不是一次性效率工具,而是一个会不断变厚的上下文资产库。
这也是我为什么越来越在意这件事:
人与人之间后面真正拉开差距的,可能不是谁用上了 AI,而是谁更早开始沉淀自己的上下文。
以前做技能是复制资料,现在更好的做法是“资料集中、技能变轻”
这里面还有一个我很认同的点,就是技能体系的搭法。
以前很多人做 AI 技能或者工作流,习惯是每个技能包里都塞一堆参考资料:
- 用户画像
- 品牌调性
- 写作规则
- 案例库
- 模板库
问题在于,这种方式短期能跑,长期一定乱。
因为你做一个技能塞一遍,做十个技能就要塞十遍。
等你哪天改了用户画像,或者更新了品牌调性,前面那十份副本就全过时了。你要么手动改十次,要么默认接受系统开始慢慢失真。
更合理的方式是什么?
把参考资料集中存在第二大脑里,技能文件只负责流程,不再负责存资料。
这样一来:
- 改一次用户画像,所有技能一起生效
- 更新一次写作风格,所有内容链路一起同步
- 新增一个案例库,多个技能都能直接调用
这种结构会比传统“技能里塞满资料”的方式干净太多。
这套玩法最狠的一点,其实是团队协作
如果只是个人用,它已经很值钱了。
但我觉得更狠的是团队场景。
因为一旦团队共用同一套可读上下文,很多原来只能靠老板自己脑补、靠熟人默契传承的东西,就开始被结构化了。
比如:
- 品牌调性
- 用户画像
- 内容边界
- 决策记录
- 项目优先级
- 常见禁区
- 复盘经验
以前这些东西往往都藏在人脑里。
新人进来以后,通常要靠不断试错、不断挨改,才慢慢接近团队标准。
但如果这些东西都已经沉淀在 AI 可读取的上下文里,情况就会完全不一样:
- 新人第一天就能读到标准
- 助理接进去就能先产出一个 70~80 分版本
- AI 先做初稿,人只负责把关
- 多个人做出来的东西,风格不会跑太偏
这就不只是“一个人效率提升”,而是整个团队的标准化开始提速。
我很喜欢它不绑平台这件事
还有一点我很认同,就是这套东西的底层其实非常朴素。
它不是建在某个封闭平台里,也不是完全寄托在某个模型厂商身上。它更像是:
- 你本地有一个知识文件夹
- 里面放的是 Markdown、文档、资料、记录
- 不同的 AI 工具都可以接进去读
这意味着什么?
意味着你的护城河不再是某一个工具本身,而是你积累下来的那份上下文资产。
今天你用 Claude,明天你换别的模型,后天你接 OpenClaw、Gemini、Kimi、DeepSeek,理论上都能继续复用同一套底料。
我特别认同这一点。
因为工具会换,模型会换,平台会换,但你自己的数据、偏好、决策和工作痕迹,才是最不该丢的东西。
如果让我来搭,我会先从最轻的一版开始
很多人一看到这种东西,就容易脑补成一个特别大的工程。
但我现在越来越偏向另一种做法:
先别追求完美结构,先把最关键的 5 类东西建起来。
比如:
1. Context
放“我是谁、我做什么、我服务谁、我现在的业务重点是什么”。
2. Daily
放每天的重要对话、会议记录、临时决定、当天推进结果。
3. Projects
每个项目单独一个文件夹,持续记录状态、卡点、下一步。
4. Resources
放模板、提示词、案例、框架、可复用素材。
5. Preferences
放写作偏好、表达禁区、常用口径、风格规范。
只要这五层先跑起来,系统就已经开始产生复利了。
后面再慢慢补:
- 竞品研究
- 团队 SOP
- 客户档案
- 决策日志
- 复盘记录
- 技能调用规则
这样比一开始就搞一套巨复杂的文件树靠谱得多。
我现在怎么看“AI 记忆”这件事
很多人会说,现在很多模型不是也有内置记忆吗?
有,但我觉得那种记忆更像“名片级记忆”。
它可能知道:
- 你是谁
- 你做什么
- 你喜欢什么风格
这当然有用,但还不够。
真正让 AI 进入深度协作状态的,不只是几个标签,而是一整套连续上下文:
- 你的项目历史
- 你的团队讨论
- 你的用户洞察
- 你的复盘结论
- 你的内容标准
- 你的任务节奏
名片和自传,差距是非常大的。
我越来越相信,未来真正决定 AI 输出质量的,不只是模型大小,而是它到底读到了你多少“活的上下文”。
最后一句,也是我现在最认同的判断
如果现在让我只给一个建议,我会说:
别只顾着找更强的 AI,先给自己存一套越来越完整的上下文。
因为模型会更新换代,工具会一茬一茬地换,但你积累下来的:
- 决策记录
- 用户理解
- 写作规则
- 项目轨迹
- 竞品研究
- 复盘经验
这些东西不会过期。
而且越早开始,优势越大。
因为后来者追的不是一个工具,而是你已经积了几个月、甚至几年的上下文资产。
我现在越来越觉得,这件事迟早会成为很多人用 AI 的分水岭。
早搭的人,AI 会越来越像自己的系统; 晚搭的人,AI 永远只是一个随叫随到、但每次都得重新解释一遍的工具。