我最近越来越确定:AI 真正值钱的地方,是把知识库持续“编译”起来

很多人还在把 AI 当成一次性问答工具,但更值得的用法,是让它持续处理原始资料、增量编译知识、回答复杂问题,再把结果回写进系统。Karpathy 这套 LLM Knowledge Base workflow 真正有价值的,不是某个工具,而是它把个人知识管理推进成了一条接近知识工程 CI/CD 的流水线。
我最近越来越确定:AI 真正值钱的地方,是把知识库持续“编译”起来

最近我看到一套让我很有共鸣的工作流:不是把 AI 当成一个临时问答窗口,而是让它长期围着你的知识库干活。
我觉得这套方法真正有价值的地方,不是用了哪个具体工具,也不是某个插件多炫,而是它把个人知识管理往前推进了一步:从“存资料”推进到“编译知识”,再推进到“持续增强”。
很多人现在已经习惯把 AI 当成聊天工具:有问题就问一下,要个总结,写段文案,关掉窗口,结束。但这种用法有一个隐性问题:每次都像重开,很多推理、判断和整理结果不会沉淀成资产。
我越来越觉得,AI 更值钱的用法不是“帮我回答”,而是“帮我长期整理、链接、回写和维护一套知识系统”。
这套 workflow 真正改变了什么?
Karpathy 这套思路其实很清楚:先把原始资料统一摄取到 raw/,然后让 LLM 增量“编译”出一个结构化 wiki,再围绕这个 wiki 做问答、输出和体检。
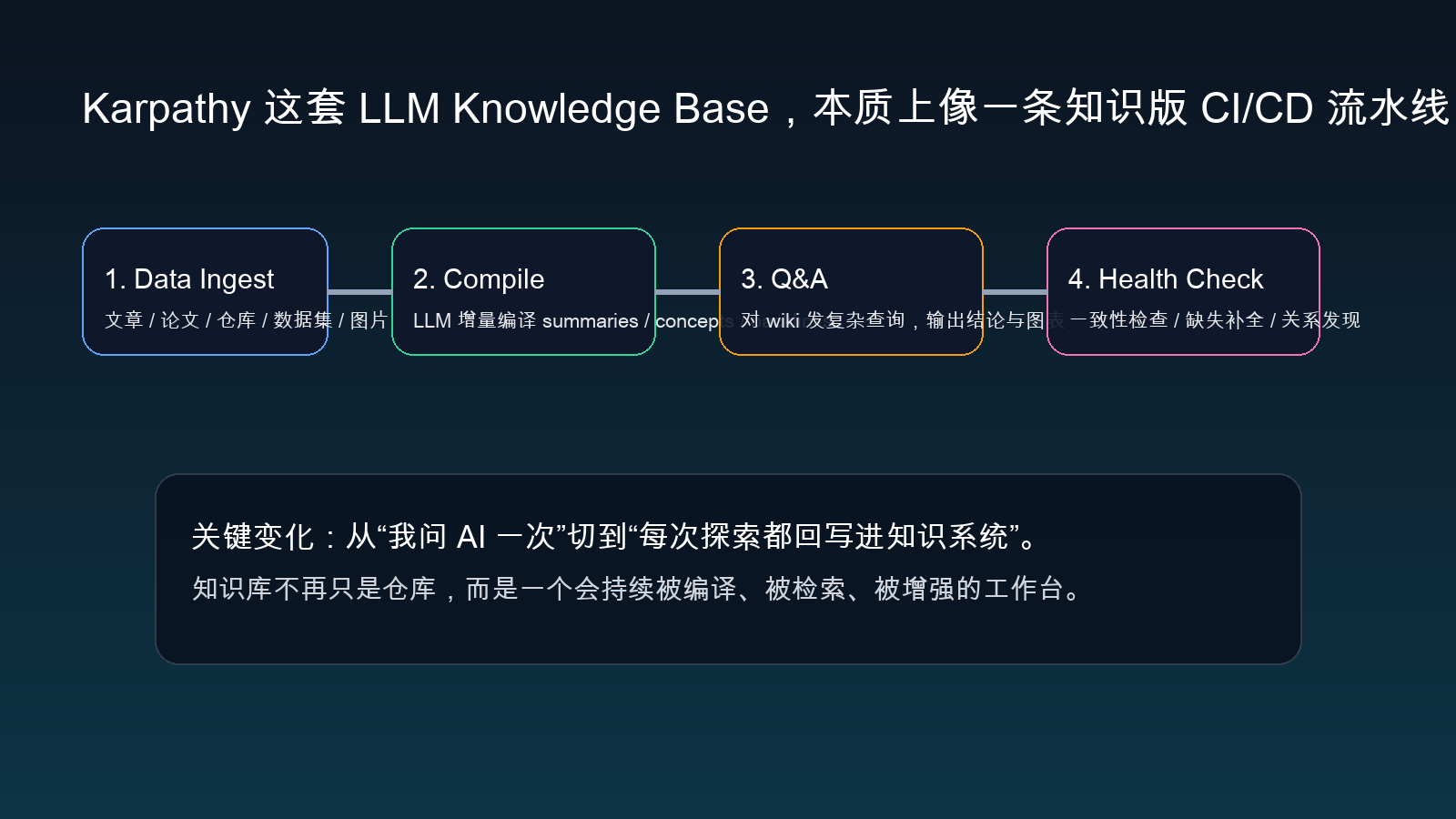
如果你用工程思维来看,它特别像一条知识版的 CI/CD:
- Data Ingest:持续喂原始资料
- Compile:把资料转成摘要、概念、索引、反链
- Q&A:对现成知识系统发复杂查询
- Health Check:检查冲突、缺口和关系
一旦这样理解,知识库这件事就不再像“堆笔记”,而更像“维护一个持续演化的知识仓库”。
为什么“编译”这个词特别准
我很喜欢这个比喻。
过去大家谈知识管理,最常见的词是整理、归档、分类、剪藏。但这些词天然带一种“手工维护”的味道。你会下意识觉得,这套系统主要靠自己勤奋、靠自己定期回头收拾。
可一旦换成“编译”,事情就完全不一样了。
“编译”意味着:
- 原始资料和产物分层
- 增量处理,而不是每次全量重来
- 中间结果有结构,不是散的
- 输出可追溯,不是临时拼凑
- 出了问题可以回查源头
这也是我为什么越来越认同:真正可持续的知识库,不应该只靠人整理,而应该靠流程和 LLM 一起维护。
它最打动我的地方,是“每次探索都会留痕”
很多人用 AI 的损耗,其实不在 token,而在“答案一闪而过”。
你今天问了一个很好的问题,AI 认真回答了;明天再遇到相关问题,你可能又得重新问一遍。看似高效,实际上没有积累。
这套 workflow 很重要的一点是:它鼓励把输出继续落回系统里。
也就是说:
- 问题不是问完就散
- 输出不是只看一眼就关
- 图表、问答、幻灯片、结论都可以回写到 wiki
时间一长,你得到的就不是一串聊天记录,而是一层一层被加工过的知识沉淀。
我觉得这是从“使用 AI”走向“利用 AI 复利”的关键分水岭。
这里最容易被忽视的一步,其实是健康检查
很多人会关注 ingest,会关注问答,会关注输出,但我反而觉得 health checks 特别重要。
因为知识库一旦变大,最容易出的问题不是“没有内容”,而是:
- 同一个概念在不同地方说法不一致
- 某些条目有标题没定义
- 来源丢了,回头查不到
- 索引没更新,新内容进了库但找不到
- 某些文章之间明明有关联,却一直没被连起来
如果没有体检,知识库迟早也会积累技术债。表面看越来越大,实际上越来越不敢信。
这也是为什么我会觉得让 LLM 定期跑一致性检查、缺失补全和关系发现特别有价值。它不是一个锦上添花的小功能,而是这套系统能否长期健康运转的关键。
我为什么觉得这比“直接上 RAG”更值得普通人学
很多人一提 AI + 知识库,第一反应就是:
- embedding 模型怎么选
- 向量数据库怎么搭
- chunk 切多大
- 检索召回率怎么调
这些当然重要,但我越来越觉得,对大多数个人知识库来说,先把知识流程跑通,比先把基础设施堆复杂更重要。
Karpathy 提到的一个现实也很关键:在规模还不算夸张的时候,只要索引和摘要维护得够好,LLM 其实已经能很好地围绕整套 wiki 工作了,不一定需要一上来就动用很重的 RAG 架构。
这点对普通人很友好。因为它把门槛从“先搭一套复杂系统”降成了“先把原始资料、结构化整理和持续回写做好”。
如果普通人想开始,最现实的做法是什么?
我觉得不用把这件事想得太重。对普通人来说,真正可执行的起步方式是:
第一步:先把原始资料入口统一
别今天存浏览器收藏夹,明天扔文档,后天贴聊天记录。先统一进入一个 raw/ 层,文章、论文、图片、仓库说明都尽量用可处理的格式留下来。
第二步:让 LLM 先做三件事
不要一上来就追求全能知识系统。先让它稳定做:
- 每篇内容的摘要
- 核心概念提取
- 索引更新
只要这三件事稳定了,整个系统就开始有雏形。
第三步:把复杂问答结果存回系统
以后遇到重要问题,不要只是问完就算。让 AI 输出成 markdown、表格、图表,甚至幻灯片,再回写进知识库。
第四步:定期体检
哪怕一周一次,让 LLM 扫一下整个系统,看看有没有冲突、缺口、孤岛条目和可补充关系。你会发现知识库的信任度会高很多。
我的最终判断
我现在越来越确定,AI 真正值钱的地方,不只是能回答问题,而是能把你的知识系统变成一个会持续生长的工作台。
这类 workflow 最强的地方,不在于把某个步骤做得多华丽,而在于它让每一次知识处理都不白做:
- 原始资料进库
- 结构化结果产出
- 查询有回报
- 输出再回写
- 系统越用越完整
这才是我眼里更像“下一代知识工具”的方向。
不是一堆脚本凑在一起,而是一条真正有复利的知识流水线。