我为什么会认真看这个 Claude Managed Agents 开源版:Agent 基础设施开始从“能跑”走向“可控”了

我最近看到一个国外团队把 Claude Managed Agents 这类生产级管理框架做成了可自部署的开源项目,最大的感受是:Agent 这件事开始真正进入基础设施阶段了。大家比拼的已经不只是模型能力,而是耐久性、观测性、安全边界和可迁移性。
我最近看到一个国外团队放出了一个 Claude Managed Agents 开源方向的项目,对应仓库是 Agentor。如果只看一句介绍,它像是在复刻“托管式 Agent 管理框架”;但我认真把 README 和对外文档看完之后,最大的感受不是“又一个 Agent 框架”,而是:Agent 基础设施终于开始从 demo 逻辑,往生产逻辑挪了。
项目地址: https://github.com/CelestoAI/agentor
过去一年大家对 Agent 的讨论,大多集中在“它能不能做更多事”“多模型协作厉不厉害”“工具调用强不强”。这些话题当然重要,但一旦真把 Agent 放进业务里,问题马上就变了:它能持续运行吗?状态能保存吗?调用链能观察吗?权限边界清不清楚?工具上下文会不会膨胀?模型换掉以后还能不能继续跑?这些问题不解决,所谓 Agent 平台最终都只是漂亮演示。
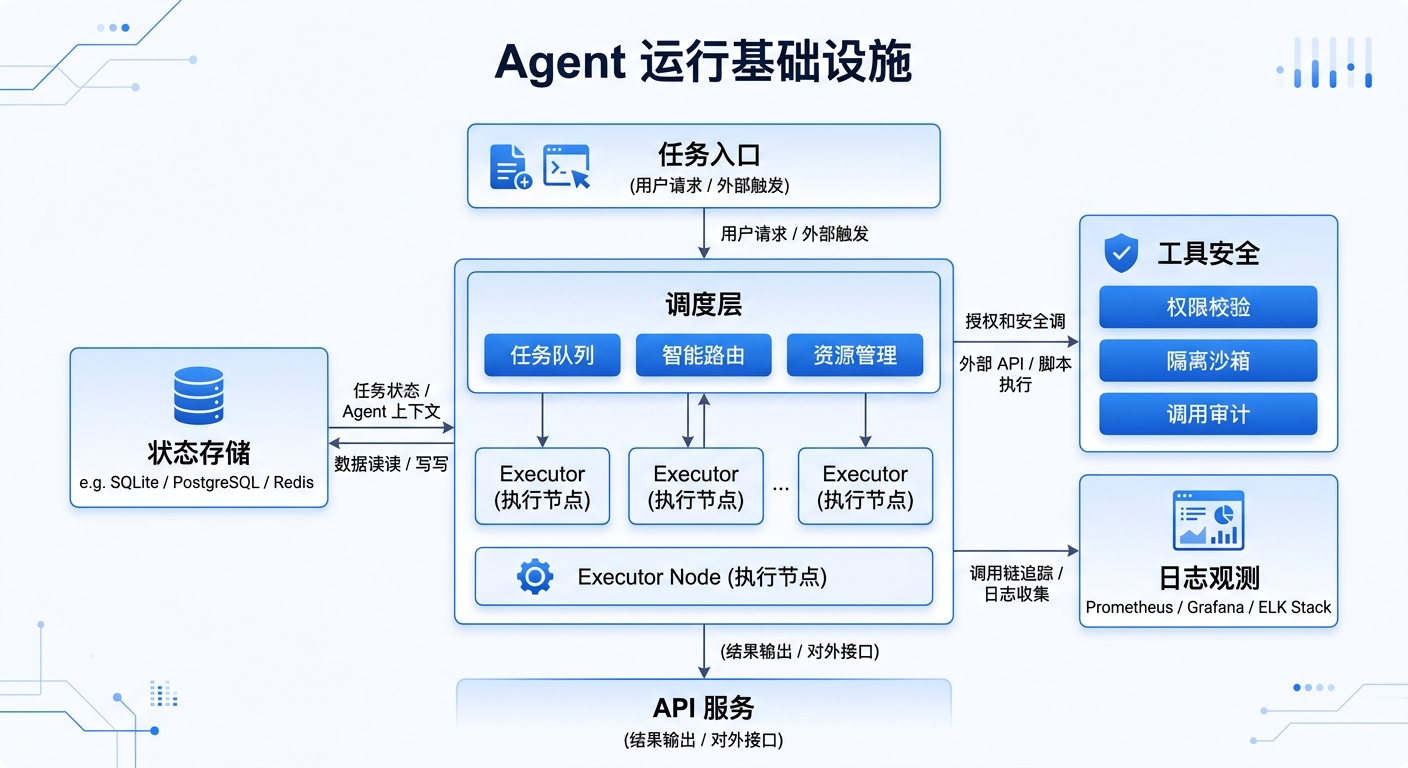
为什么我觉得这个方向比“再做一个 Agent demo”重要得多
Agentor 公开强调的几个关键词非常关键:durability、observability、security、agent-to-agent、MCP & tool security。如果你平时只是把 Agent 当聊天机器人,这些词可能显得偏工程;但只要你做过长任务、后台任务、多人协作任务,就会知道这些词几乎就是生死线。
我特别认同“durability”被摆到前面。很多 Agent 跑得起来,但跑不久。会话断了、服务挂了、上下文丢了、依赖爆了,任务就废了。一个真正像样的 Managed Agent,不应该只在你盯着终端的时候活着,而应该能在更长时间尺度上稳定执行、恢复和继续。说难听点,能完成一次不值钱,能反复完成才值钱。
observability 也是一样。你不可能把生产系统交给一个“看起来应该在工作”的黑盒。Agent 为什么卡住、哪一步耗时最多、哪个工具最容易失败、哪个任务链路最常崩,如果没有可观测性,你根本没法优化,更谈不上让团队信任它。
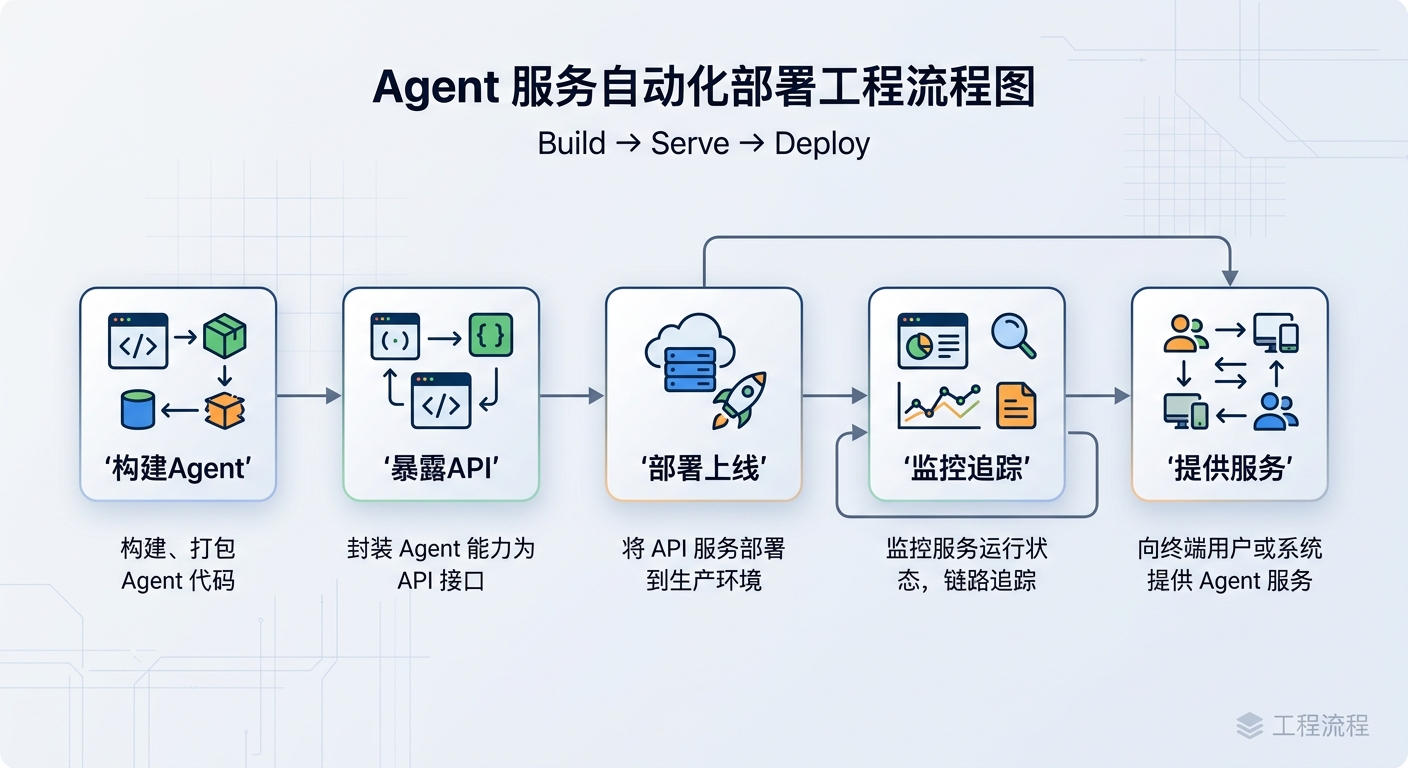
我最看重的是:它把 Agent 当成服务,而不是当成脚本
 从 README 看,Agentor 的路线非常明确:不是做一个只能本地玩的 prompt 工具,而是让你能够 build、serve、deploy 一个真正可访问的 Agent 服务。文档里甚至直接给出“几行代码定义 Agent,然后 serve,再通过 HTTP
从 README 看,Agentor 的路线非常明确:不是做一个只能本地玩的 prompt 工具,而是让你能够 build、serve、deploy 一个真正可访问的 Agent 服务。文档里甚至直接给出“几行代码定义 Agent,然后 serve,再通过 HTTP /chat 调用”的模式。这个动作很小,但意义很大。
因为一旦你把 Agent 视为服务,而不是脚本,整个工程思路就完全不同了。你会开始关心:
- 如何暴露 API;
- 如何管理权限;
- 如何对接内部工具;
- 如何部署到 serverless 或独立环境;
- 如何让多个 Agent 之间用协议通信;
- 如何让工具不是越接越乱,而是能被搜索、被裁剪、被审计。
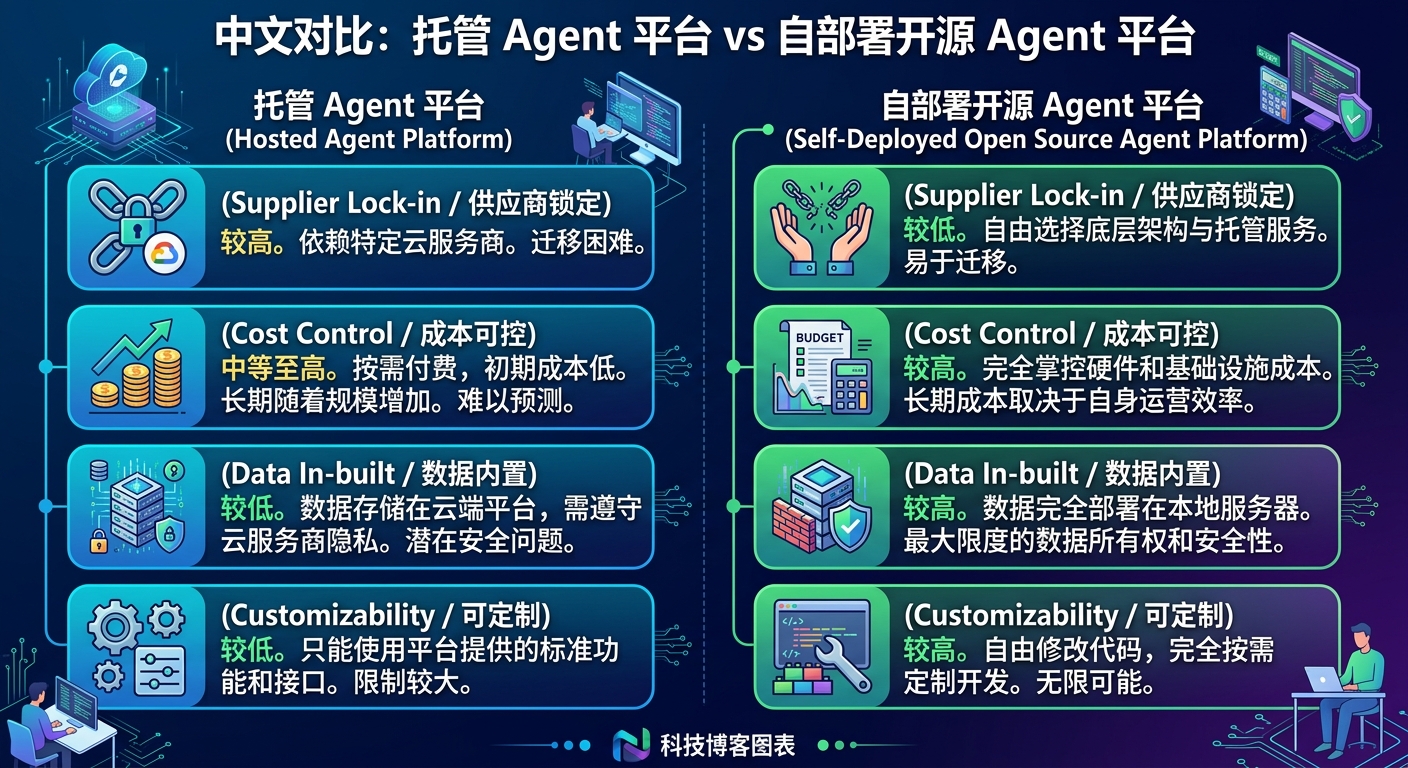
这正是我觉得 Managed Agents 这个方向真正有价值的地方。它不是“帮你多做一件事”,而是让 Agent 进入可治理状态。只有进入可治理状态,Agent 才可能成为组织资产,而不是个人玩具。
这个开源版释放出来的几个信号很明确
第一,大家已经不满足于托管黑盒了。
官方托管方案的优点当然很明显:开箱即用、体验统一、文档完善。但一旦公司真的把重要流程交给它,焦虑也会同步出现:成本怎么控?日志看不看得到?数据能不能内置化?策略能不能自定义?万一平台调整价格和策略怎么办?
开源替代出现的意义,不只是“更便宜”,而是让团队重新拿回架构主导权。你不必百分百复制官方实现,只要能把核心抽象拿到自己手里,剩下的工程演化空间就大了很多。
第二,工具安全开始变成头等问题。
Agentor 把 MCP 与 tool security 放到显著位置,我觉得这非常现实。因为 Agent 一旦接工具,就不再只是“生成内容”,而是有机会读写数据、调系统、跑流程。这个时候最危险的不是模型胡说八道,而是权限边界不清。谁能调用什么、什么情况下能调、调完如何审计,这些都不能靠“希望模型乖一点”解决,必须靠框架层设计。
第三,Agent-to-Agent 正在从概念走向协议化。
文档里提到 A2A protocol、agent card、标准化消息交互。这说明一个趋势:未来 Agent 不会只是单体,而会像服务网格一样存在发现、协作、汇报和交接问题。谁先把这套协议层打稳,谁就更容易形成生态。
我觉得它真正打中的,是团队级需求
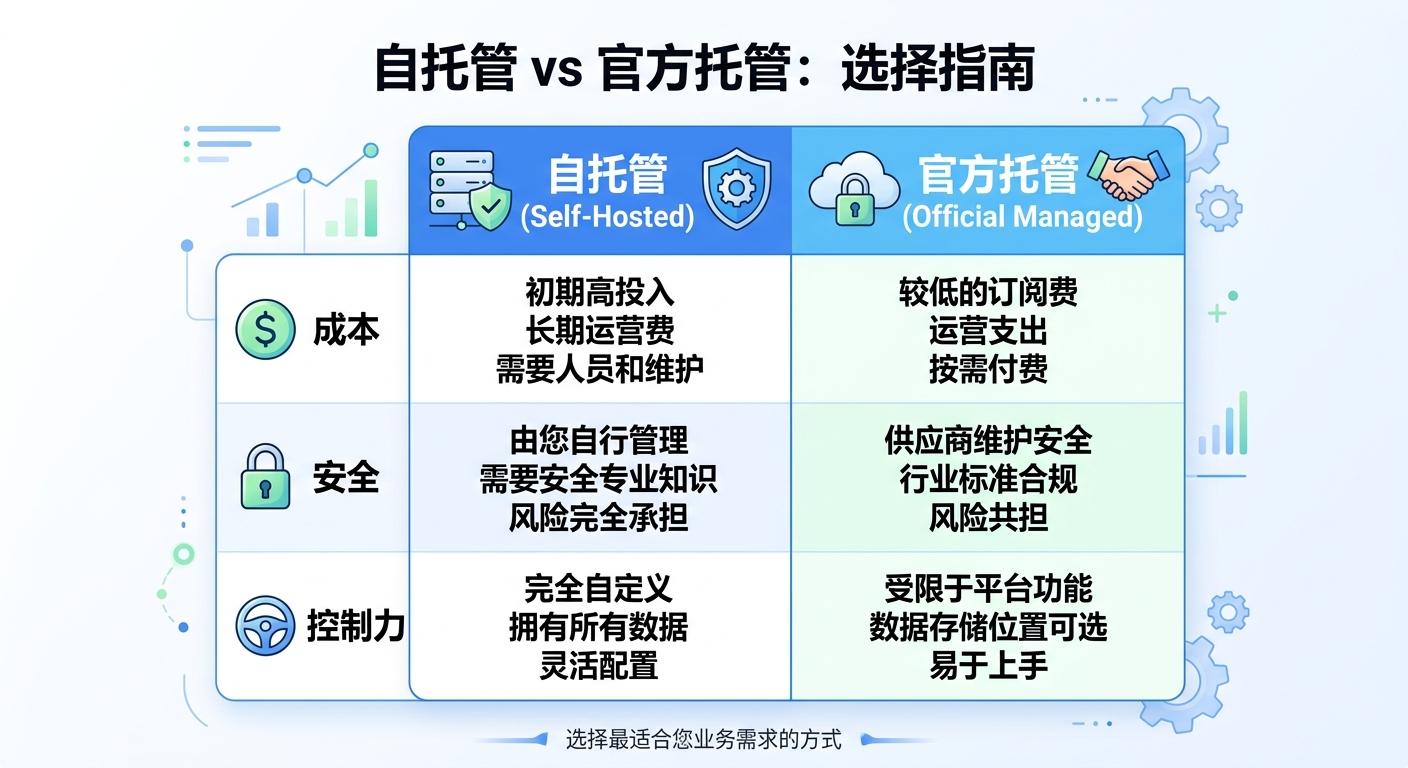 对个人开发者来说,一个能跑的脚本往往已经够爽。但对团队来说,能跑只是门槛,可维护、可部署、可追踪、可继承 才是价值所在。Managed Agents 之所以被热议,就是因为越来越多人开始意识到,Agent 不是“多调用几个 API”那么简单,而是一个新的基础设施层。
对个人开发者来说,一个能跑的脚本往往已经够爽。但对团队来说,能跑只是门槛,可维护、可部署、可追踪、可继承 才是价值所在。Managed Agents 之所以被热议,就是因为越来越多人开始意识到,Agent 不是“多调用几个 API”那么简单,而是一个新的基础设施层。
你可以把它类比成早期 Web 服务的发展过程:一开始大家只是写页面、写接口;后来大家开始要网关、日志、监控、灰度、权限、指标、弹性扩容。Agent 现在也在走这条路。谁能先把这些配套能力做成框架,谁就不是在卖单次能力,而是在卖长期运行能力。
如果你现在就在做 Agent 平台,我建议你重点盯三件事
第一,看状态管理和长任务恢复。 Demo 阶段,大家都爱展示“十秒钟完成一个漂亮任务”;生产阶段,真正决定体验的是“一个三十分钟任务中间挂了以后还能不能接着跑”。
第二,看观测和调试链。 如果框架不给你清晰的 tracing、任务日志、工具调用脉络,后面会非常痛苦。因为你连问题出在哪都不知道。
第三,看安全抽象是不是在框架层完成。 工具权限、MCP 授权、跨 Agent 通信、内部服务暴露边界,这些最好在架构里默认可控,而不是全靠业务方自己补洞。
我的结论很简单
我认为这个 Claude Managed Agents 开源方向值得关注,不是因为它“又做了一个很像官方的东西”,而是因为它证明了一件事:Agent 基础设施的竞争,已经从炫能力进入炫工程质量的阶段。
以后真正分出高下的,不会只是哪个模型更会写,而是谁能把 Agent 变成可靠服务:有状态、有边界、可部署、可观察、能协作、能审计。只要这个方向继续往前走,开源生态会很快把“Managed Agents”从品牌概念变成通用能力。
对我来说,这比单次模型升级更重要。因为模型再强,如果没有可靠的承载层,最后还是只能停留在演示视频里。可一旦承载层成熟,Agent 才会真正进入企业系统、个人流程和长期工作流。
这也是我最近看这类项目时最明显的感受:大家不再满足于让 Agent“看起来很聪明”,而是开始要求它“长期可用、出了问题能定位、迁移成本可接受”。一旦行业共识切换到这里,下一波真正有价值的项目就会很快浮出来。