英伟达的终极底牌:数据中心如何变身"超级印钞机"?

在人工智能的浪潮中,我们每天都在和Token打交道——无论是一行自动生成的代码,还是一篇结构严谨的商业计划书,其底层都是大模型吐出的一连串Token。
英伟达的终极底牌:数据中心如何变身"超级印钞机"?
在人工智能的浪潮中,我们每天都在和Token打交道——无论是一行自动生成的代码,还是一篇结构严谨的商业计划书,其底层都是大模型吐出的一连串Token。
但你有没有想过,这些Token究竟是从哪里"变"出来的?
2024年的GTC大会上,英伟达CEO黄仁勋抛出了一个极具颠覆性的概念:"AI Token工厂"。
在他的构想里,未来的数据中心将彻底撕掉"存储仓库"的旧标签,摇身一变成为轰鸣运转的"制造车间"。它们不再以保管数据为己任,而是以生产Token为唯一使命。
在这个新时代,Token就是智能经济的"原油"和"货币",而数据中心,就是一台台日夜不息的超级印钞机。
这绝非一个华而不实的比喻。从"仓库"到"工厂"的范式转移,正在彻底重塑整个算力产业的商业底层逻辑。今天,我们就来拆解这座"Token工厂",看看它是如何将电力转化为黄金的。
---
01 范式跃迁:从"成本中心"到"生产中心"
要理解Token工厂的颠覆性,我们必须先厘清传统数据中心与AI数据中心的本质区别。
在传统模式下,数据中心扮演的是"后勤仓库"的角色。企业租用服务器,看重的是存储容量、网络带宽和可用性。算力在这里是纯粹的**"成本中心"**,它的任务是支撑业务不宕机,按部就班地按资源(CPU、内存)收费。
但在AI时代,游戏规则变了。
AI数据中心是一座名副其实的"工厂"。原材料(数据)和配方(大模型权重)从一头送进去,机器轰鸣之后,另一头吐出的产品就是Token。算力不再是幕后的支撑者,而是直接创造价值的**"生产中心"**。
这就好比过去的面包厂只负责存放面粉,现在的工厂则直接把面粉烘焙成精致的面包出售。智能客服的回答、设计师的AI绘图、程序员的Copilot,全都是这条流水线上的标品。
因此,衡量这座工厂的核心指标变了:不再是存储量,而是Token吞吐量(每秒产量)、每瓦特产出Token(能效比)、以及每美元产出Token(成本率)。
---
02 揭秘流水线:从一度电到万亿Token
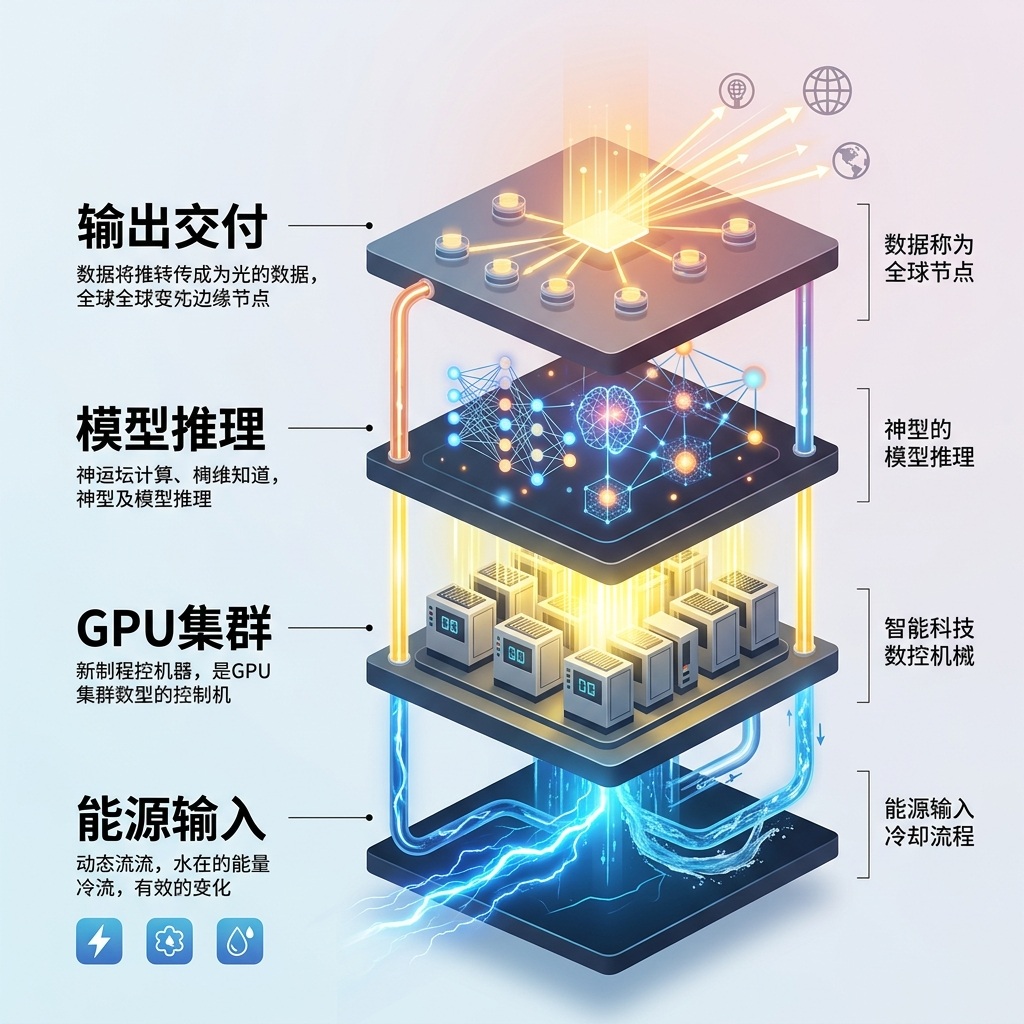
一座现代化的Token工厂,其内部运作的精密程度不亚于任何顶级重工业制造厂。它的生产线可以分为四个核心层级:
第一层:能源输入(动力源)
一切奇迹的起点,是庞大的电力。
以一个配备10万张H100 GPU的超级数据中心为例:单张H100峰值功耗700W,10万张就是70MW。算上冷却、网络和存储损耗,总功耗直逼100MW。
这是什么概念?它一年的耗电量高达8.76亿度,足以撑起一个30万人口城市的全年运转。

第二层:GPU集群(机床群)
电力输入后,迎接它们的是数以万计的"数控机床"——GPU。
这些GPU通过高速网络互联,在调度系统的指挥下,夜以继日地处理复杂的矩阵运算。集群的协作效率,直接决定了这座工厂的产能上限。
第三层:模型推理(加工工艺)
这是Token诞生的产房。当用户输入一句话,推理引擎迅速将其转化为Token,送入大模型中进行概率计算,然后逐字生成输出的Token。
为了提高良品率和产量,工厂需要不断优化"工艺":比如采用混合专家模型(MoE)架构、降低量化精度(INT8)、扩大批处理规模、以及使用KV缓存技术避免重复计算。
第四层:输出交付(物流网)
生成的Token必须以最快的速度送达用户屏幕。这就要求工厂在全球部署边缘节点,通过冗余设计和负载均衡,确保低延迟和高可用性。
那么,一座这样的超级工厂,产能到底有多恐怖?
以目前的能效估算,一个100MW的数据中心满负荷运转,每小时能产出约1000万到2000万个Token,年产能可达千亿级别。
然而,放到全球视野下,这仅仅是九牛一毛。预计到2026年,全球日均Token消耗量将突破180万亿。要填饱这个无底洞,全球至少需要650座这样的超级工厂。 这也是为什么全球算力基建正在以史无前例的速度狂飙。
---
03 财务密码:出厂价与零售价的暴利差
既然Token工厂是制造企业,我们就必须用审视制造业的眼光来看待它的财务模型。
决定一家Token工厂生死的核心指标有两个:
1. 能效指标:每瓦特产出Token
工业时代看"吨钢耗电",AI时代看"每度电产Token"。得益于英伟达B200等新一代芯片的迭代,以及算法层面的优化,目前行业能效每年正以30%-50%的速度提升。未来,每度电产出数十万甚至百万Token将成为常态。
2. 成本指标:每美元产出Token
如果把硬件折旧、电费、冷却、运维和租金全算上,一个优化良好的数据中心,生产一个Token的实际成本仅需约0.0000014到0.000007元人民币。
这就引出了一个极具诱惑力的问题:既然出厂价低到几乎可以忽略不计,为什么我们买API时,还要按几分钱/千Token来付费?中间的巨额差价去哪了?
答案藏在科技公司的财报里:研发摊销、品牌溢价和暴利空间。
你支付的API零售价,不仅包含了昂贵的模型前期训练成本,还包含了OpenAI或Anthropic们庞大的研发薪资、市场营销费用,以及作为行业头部玩家收取的"智商税"或"品牌溢价"。
出厂价与零售价之间巨大的鸿沟,正是当前大模型厂商跑马圈地、甚至大打价格战的最大资本。
---

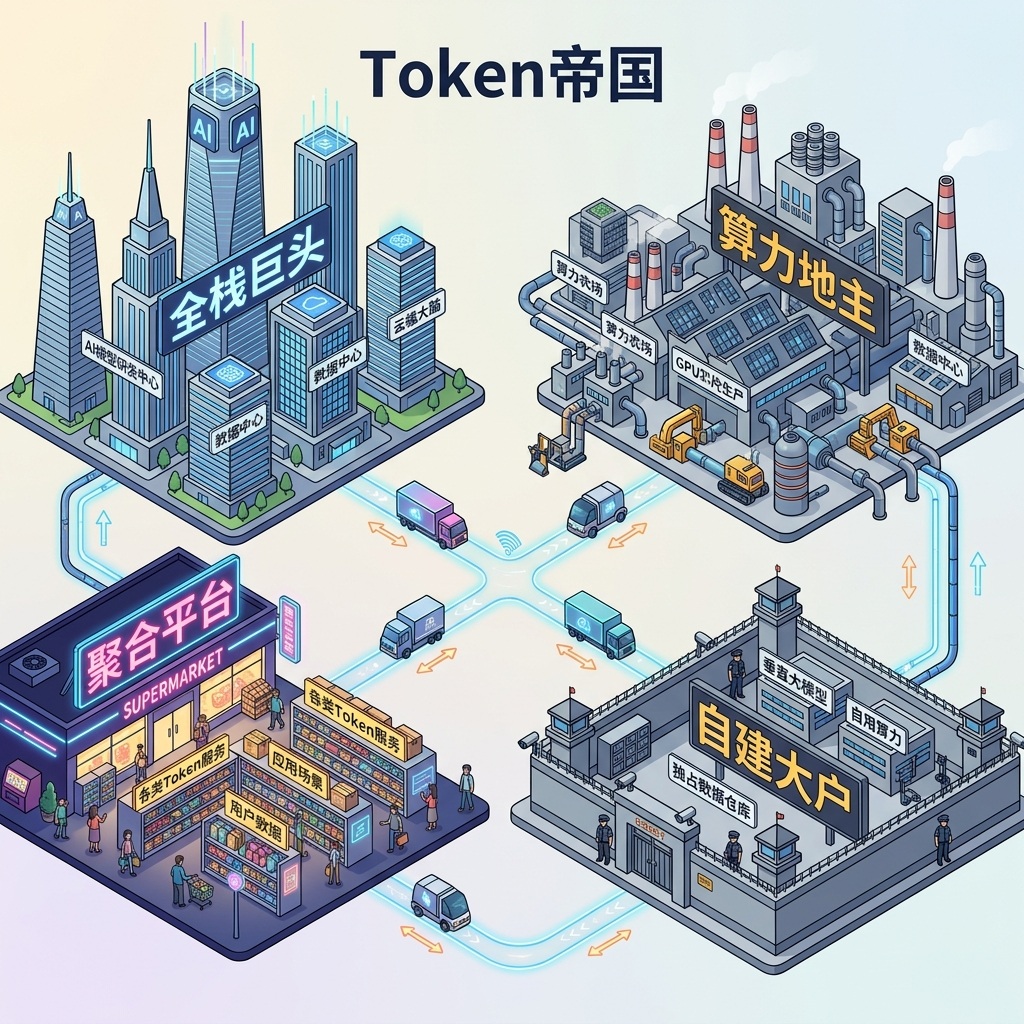
04 玩家图谱:谁掌握了"印钞机"的开关?
在这场Token制造的军备竞赛中,市场上的玩家主要分为四大阵营:
* 全栈巨头(如OpenAI、Google): 自己握有模型产权,自己建数据中心,直接向终端用户零售Token。优势是端到端把控,利润率最高,但极度烧钱。
* 算力地主(如AWS、阿里云): 提供云算力租赁或托管API。他们靠规模效应摊薄成本,是算力时代的"包租公"。
* 聚合平台(如OpenRouter): 相当于Token界的"中间商"或"超市",把各家大模型的API聚合起来供用户比价使用。赚取微薄差价,主打一个便利性。
* 自建大户(如顶尖金融机构、政府部门): 出于数据安全和长期成本的考量,直接买GPU自建私有Token工厂。门槛极高,但自主可控。
---
05 终局推演:从"卖面粉"到"卖面包"
尽管如今的Token工厂已经足够令人惊叹,但它的终局远不止于此。
目前,我们向工厂购买的是"原始Token"——你需要绞尽脑汁写Prompt(提示词),自己校验和排版输出内容。这就好比你去工厂买了一袋面粉,还得自己和面、发酵、烤面包。
未来的Token工厂,将进化为真正的"智能工厂"。
你不再需要购买Token,而是直接下达任务指令:"帮我分析这份财报并生成PPT"。工厂内部的Agent(智能体)调度系统会自动规划、拆解任务、调用不同模型、执行校验,最后直接把精美的PPT交到你手上。
计费模式也将从"按Token计费"升级为**"按任务结果计费"**。这不仅是产品形态的升级,更是生产力交付方式的降维打击。
当然,通往未来的道路上也有隐忧。当Token工厂的规模呈指数级扩张,它正在成为一只吞噬能源的巨兽。预计到2030年,全球数据中心的耗电量可能达到全球总用电量的10%。排队抢电、水资源消耗、碳排放压力,将成为未来算力博弈中不可忽视的紧箍咒。
对于中国市场而言,虽然面临高端GPU禁令等挑战,但凭借西部低廉的绿电优势(东数西算)、国产算力的奋力追赶,以及以DeepSeek为代表的算法架构创新,我们完全有机会在全球Token制造网络中,占据不可替代的生态位。
---
主编观点:算力即权力,Token即财富
回顾人类商业史,每一个时代的霸主,都掌握了那个时代最核心的生产要素:土地、石油、资本。
而在智能时代,数据中心就是新的油田,Token就是新的黄金。
将数据中心视作"印钞机",不仅是一个精妙的商业比喻,更是理解未来十年宏观经济周期的一把钥匙。当电力通过GPU的矩阵运算,凝结成一个个包含人类智慧的Token时,一种全新的价值创造机制已经诞生。
在这个新世界里,谁能以最低的成本生产最高质量的Token,谁能将Token转化为最极致的智能服务,谁就握住了通向下一个时代的入场券。
